Deeptime and the Bonaire Baseline
So in 2023 I was living in Bonaire, scuba diving, and looking for a coral research project I could do. I had picked up some photogrammetry skills working with ReefRenewal on a kelp restoration project. I love ocean science. And apparently I love big data, because I thought if I could do small 100 square meter scans in California, why not do 2000 square meter scans in the Caribbean?
The answer it turns out, is because managing that much data is way harder than I thought it would be. The existing leader in the AI annotation space, TagLab, would only let us view a tiny part of each scan, requiring us to slice up our scans and process them in very inconvenient chunks. And although I was working with STINAPA, the national parks of Bonaire, we didn’t have the budget for some fancy cloud server, and the Azure file share we did have access to kept choking on sharing the 10+ GB scans. And we had like 18 of them. So we managed to get a little of the data annotated but the project stalled from there.

And fast forward to now, I’m still on sabbatical with the design world falling around me because of AI tools and I’m vibe coding projects left and right. I thought, maybe I could build the tool that we didn’t have back then. I’ve always wanted a big data annotation tool that would stream data to researchers around the world. Don’t you want that too?
So last week I started pushing Claude around in VSC with a plan that I crafted with Gemini. Does this sound crazy? yes. Did it work? yes.
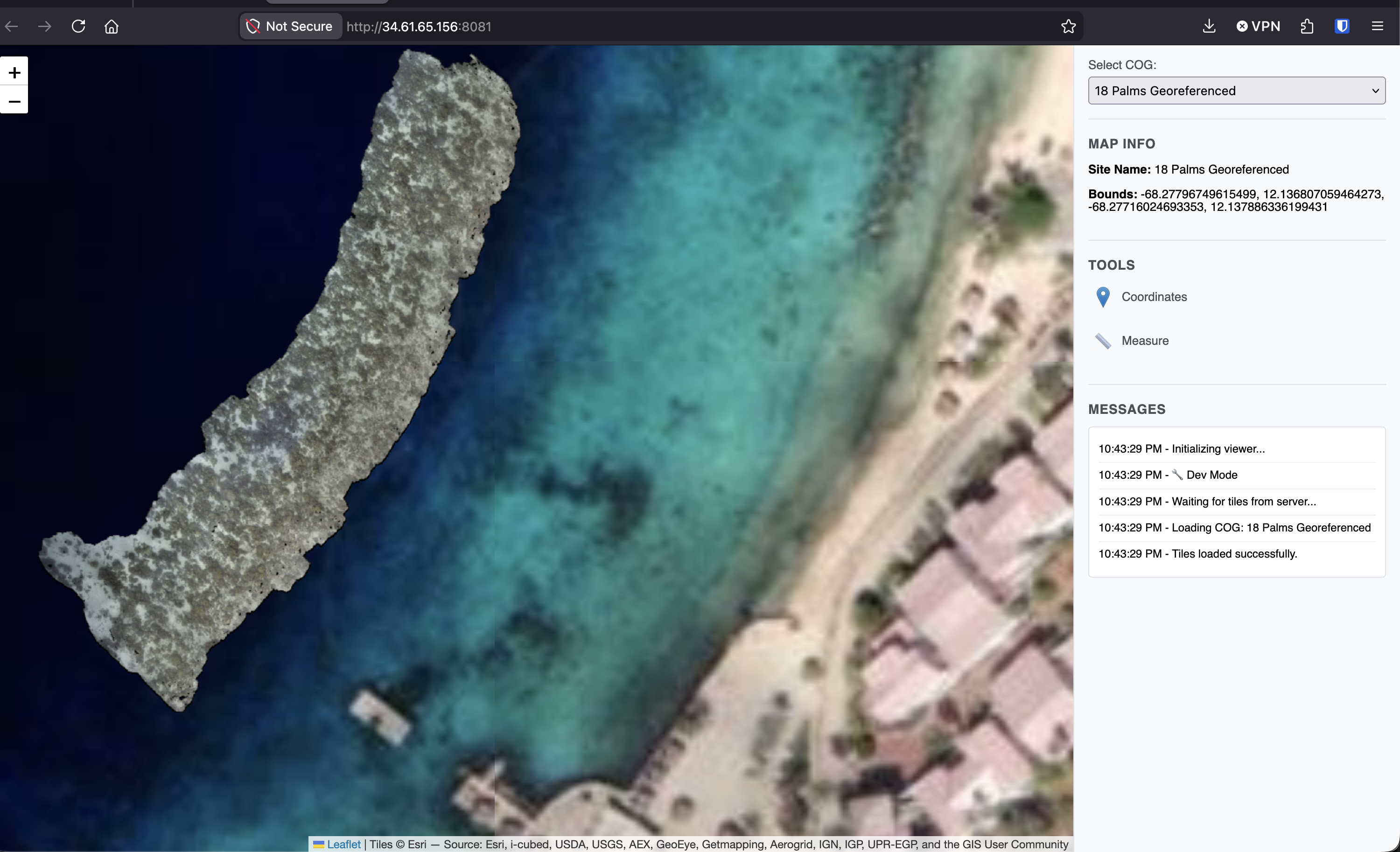
But almost none of the original plan is intact. Basically the google cloud bucket with titiler is the only remaining part of the stack from that first plan that worked. And that’s vibe coding, really any development. Gemini hallucinated a bunch of features that didn’t exist and didn’t plan for contingencies that we ran into. I spent days building scripts to manage gigabytes of geotiffs, trying to generate valid cog files that would sit on the google bucket Claude provisioned for me. It took us 3 or 4 times to get the titiler configuration correct. And the browse server, which is under development here: http://34.61.65.156:8081
While Gemini hallucinated features and Claude generated hundreds of lines of unnecessary code, I patiently guided my team of agents down a path that finally led to working software. And I think this is because I have broad experience and domain specific expertise. This is going to be the path forward for designers and developers, I think this Wall Street Journal article basically describes what I’m doing on this project. Before AI it would have been impossibly complex for me to build this tool and have it stream gigabytes of high resolution coral data to you. But now, with care, I’m on a path to empower researchers. I mean, it’s still a prototype but I don’t see anything stopping me.

And why am I doing this? Because in 2023 Stony Coral Tissue Loss Disease hit the reef in Bonaire. The data that we collected at that time we can never get again because the disease killed such a large portion of the reef, hitting certain species particularly hard. This archive represents a window into a time that we won’t forget. And the hope is that one day, future generations will return the reef to its previous glory.
View the project on Github